
Maîtriser la modern data stack ne peut se faire uniquement par des certifications ou des tutos. Rien ne vaut un vrai projet personnel, surtout lorsqu’on souhaite progresser en tant qu’analytics engineer ou data engineer.
Bonne nouvelle : on peut tout faire gratuitement avec le généreux Free Tier que propose notamment GCP (même après la période d’un mois gratuit) et quelques outils open-source.
🎯 Objectif : un data product complet
Dans ce projet, j’ai voulu simuler une vraie architecture orientée usage :
- Extraction de données depuis des outils SaaS métiers (ex. ServiceNow, NetSuite…)
- Transformation analytique (modélisation, métriques prêtes à l’emploi)
- Visualisation ET cas d’usage IA (chatbot analytique, scoring AML…)
- Architecture scalable, documentée, portable
🧱 Architecture technique: ELT Cloud Native
L’architecture suit le schéma classique ELT + Semantic Layer :
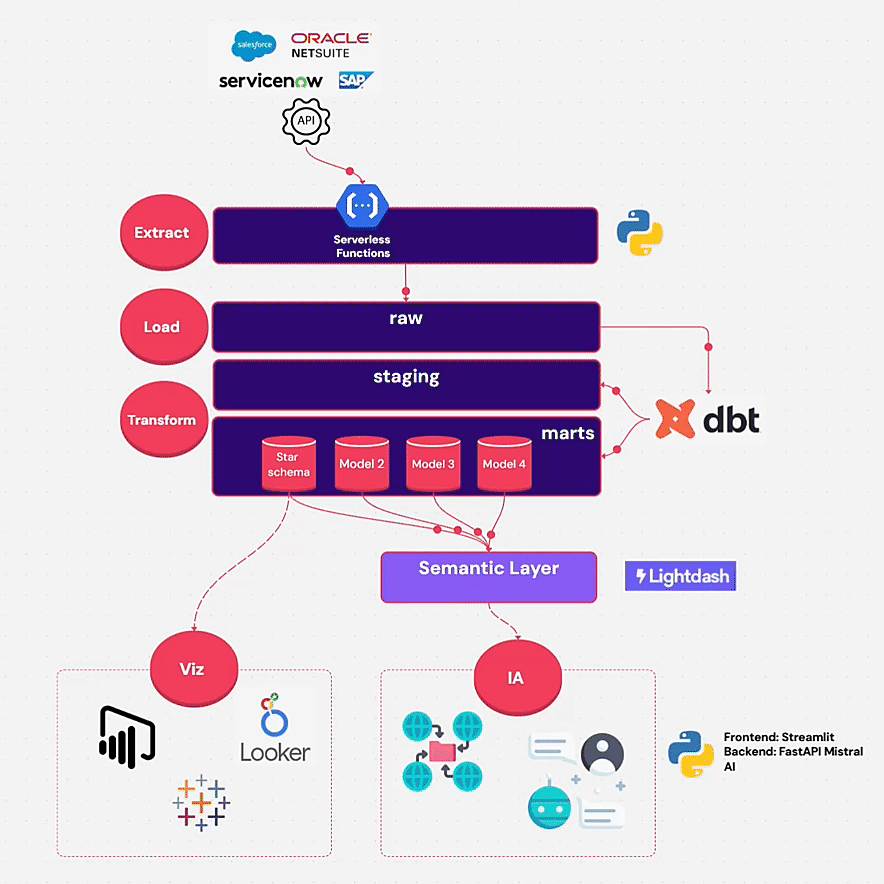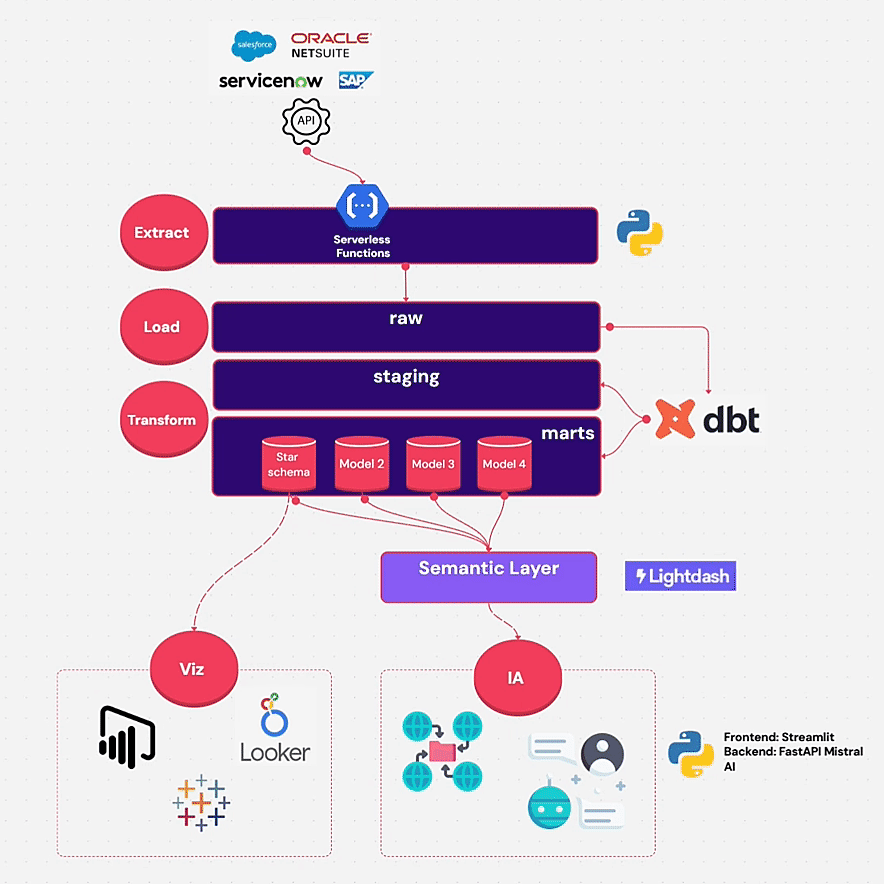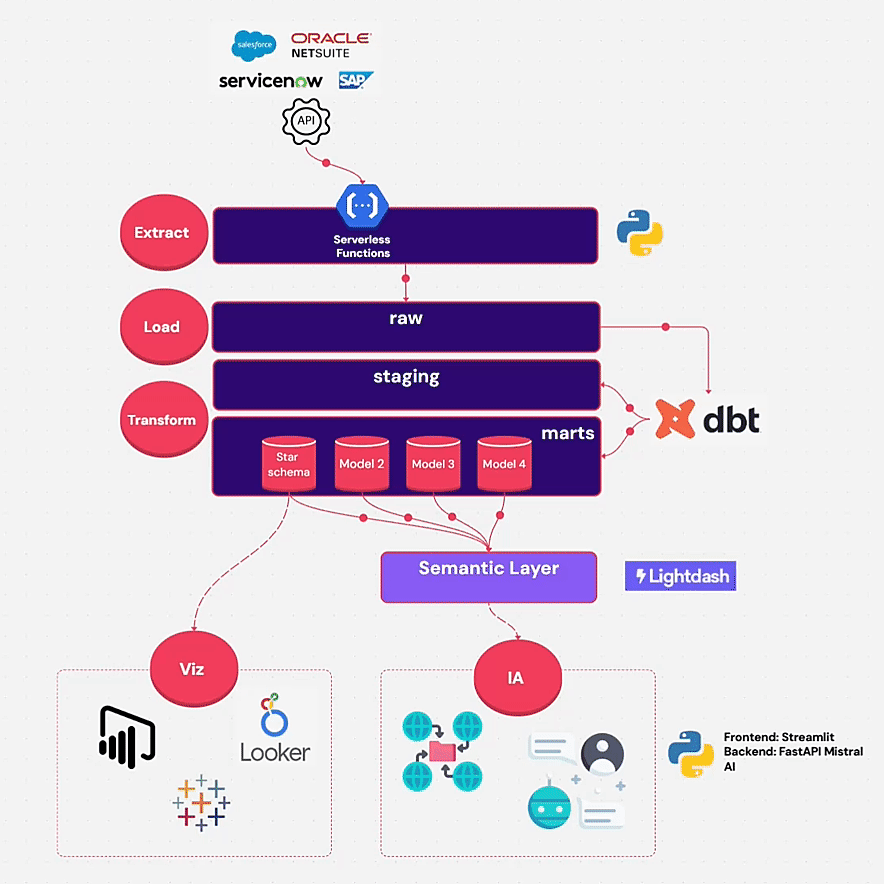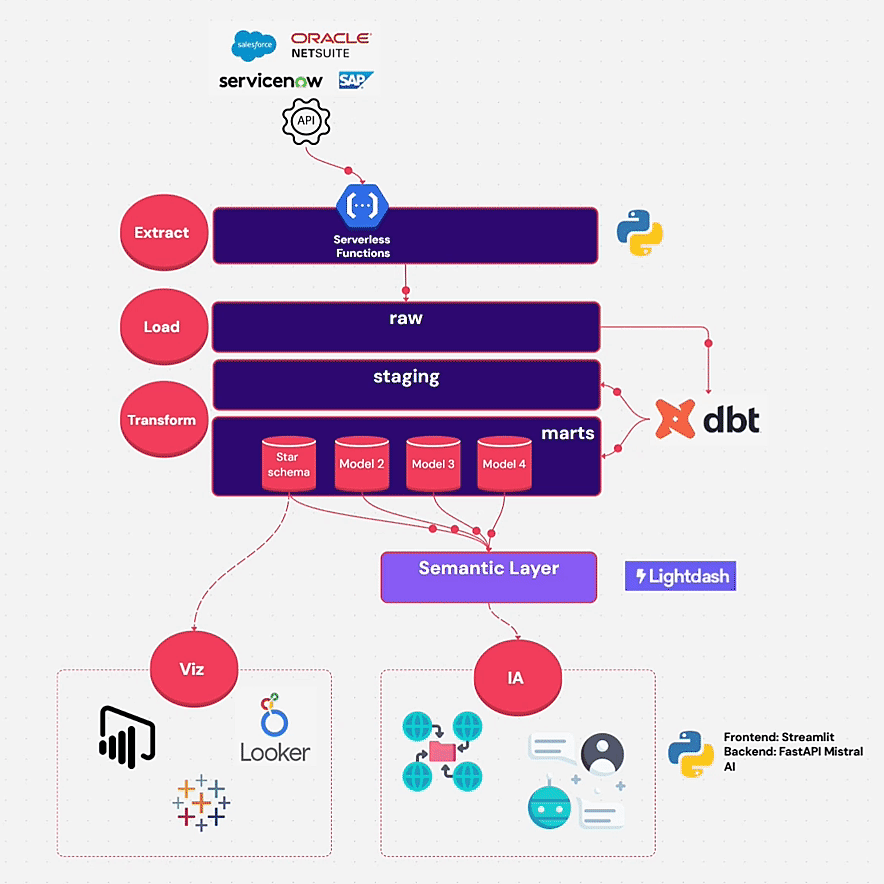
🧩 Outils utilisés :
| Étape | Outil(s) | Free Tier ? |
|---|---|---|
| Extract | Python + Cloud Functions | ✅ 2 millions d’appels/mois (400k GB-s / mois) |
| Load | BigQuery (données brutes partitionnées) | ✅ 10 Go stockage + 1 To requêtes/mois |
| Transform | dbt Core ou dbt Cloud | ✅ Core : open-source Cloud : gratuit jusqu’à 1 développeur + 1 job/jour |
| Semantic | Lightdash / dbt metrics | ✅ Lightdash OSS self-hosted dbt metrics inclus dans dbt |
| Viz | Looker Studio, Power BI | ✅ Looker Studio gratuit Power BI Desktop gratuit avec connecteur BigQuery |
| IA | Streamlit + FastAPI + Mistral AI local | ✅ 100% open-source (à héberger localement) |
🚀 1. Extraction des données (E)
Les progiciels comme ServiceNow ou Salesforce, ainsi que la plupart des CRM & ERP phares proposent leur API native.
On déclenche une Cloud Function GCP (toujours gratuite en usage léger) toutes les nuits pour collecter les nouvelles données.
Exemple (simplifié) :
import requests
from google.cloud import bigquery
def extract_to_bq(request):
response = requests.get("https://api.servicenow.com/incidents")
incidents = response.json()
client = bigquery.Client()
table_id = "mon_projet.raw.servicenow_incidents"
errors = client.insert_rows_json(table_id, incidents)
if errors:
raise Exception(f"BigQuery errors: {errors}")
📦 2. Chargement dans BigQuery (L)
Les données sont stockées dans un schéma raw, partitionnées par date pour optimiser le coût.
GCP offre 1 To de requêtes BigQuery gratuites par mois, ce qui est largement suffisant pour un projet perso.
💡 Astuce : éviter les SELECT *, activer le partition pruning et faire attention aux types (les STRING sont plus coûteux que les INT).
🤖 Optimisation: pense à gérer une table de temporaire qui te servira ensuite à gérer plus facilement un MERGE dans le schéma raw cible
🔧 3. Transformation (T) avec dbt
Le moteur de transformation, c’est dbt Core.
Les modèles suivent 3 niveaux :
stg_*: normalisation, typage, renommageint_*: jointures, enrichissementmart_*: modèles finaux en star schema (ex : ici table de fait incident et ses dimensions)
💡 dbt permet aussi de tester les modèles, générer la doc, et calculer des metrics partagées via dbt_metrics ou Lightdash.
🧠 Semantic Layer
Cette brique est cruciale pour éviter que chaque outil redéfinisse les KPIs différemment.
🔧 Options utilisées :
- dbt metrics : centralise la logique métier dans le code
- Lightdash : interface BI directement connectée à dbt
👀 Exemple : calculer le % de tickets résolus dans les 24h directement dans le layer, sans dupliquer la logique côté dashboard.
📊 Visualisation
Les datasets finaux peuvent être exposés :
- via Tableau Public, Power BI, Looker Studio
- Dans l’idée de rester en Free Tier au maximum, je conseillerai ici plutôt Power BI ou Looker Studio afin de bénéficier du connecteur BigQuery sans passer par un abonnement professionnel.
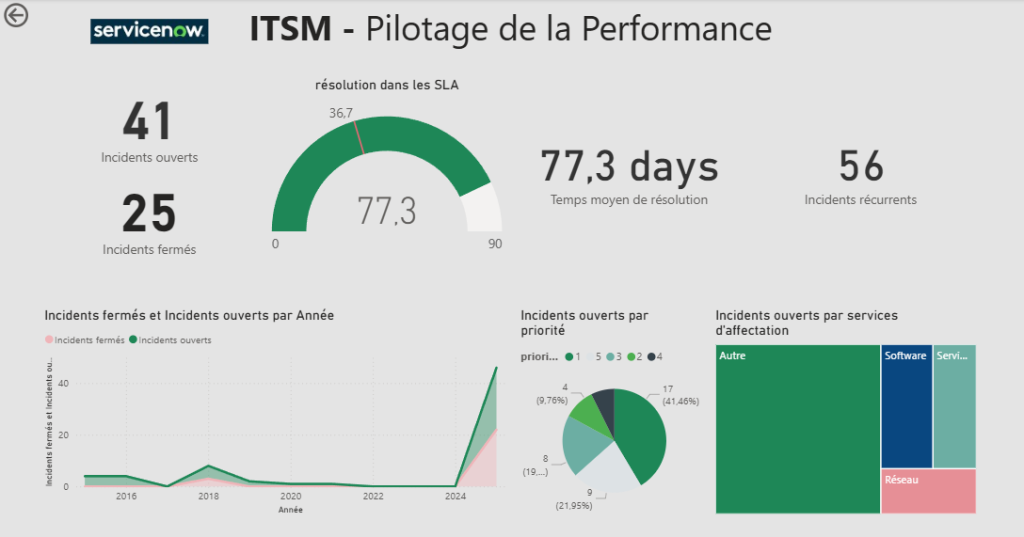
Exemple de dashboard (ici j’ai donc utilisé power BI):
🤖 Intégration IA
C’est le petit bonus du projet : brancher une IA open-source (Mistral 7B local) pour dialoguer avec ses propres données.
👷 Stack utilisée :
- FastAPI en backend (API de questions SQL vers BigQuery)
- Mistral AI local via Ollama
- Streamlit en interface simple et rapide
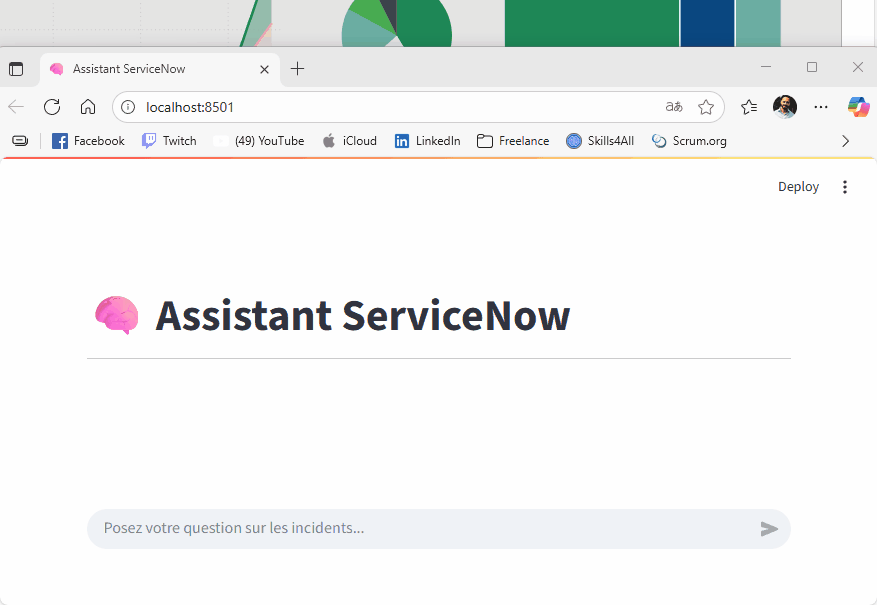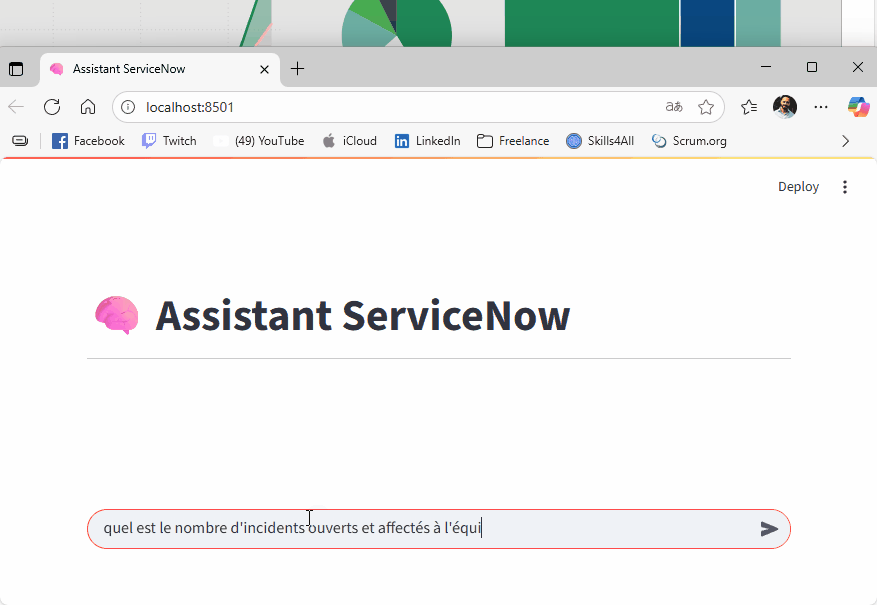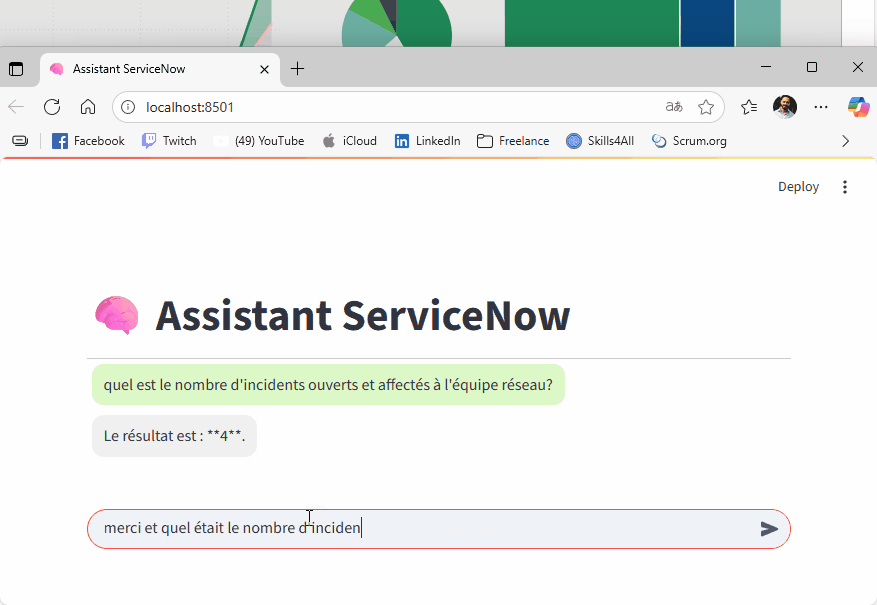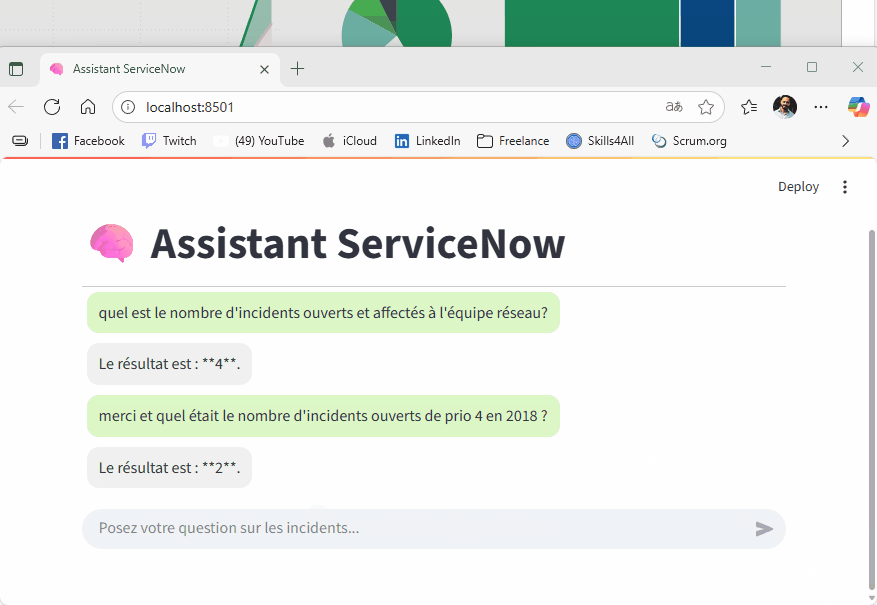
On peut poser des questions comme :
« Quels sont les incidents critiques non résolus depuis plus de 3 jours ? »
Le tout en langage naturel..
exemple (prototype) avec Ollama et le modèle mistral en local (plus lent que les API externes mais gratuit):
📦 Déploiement & Orchestration
Tout est hébergé sur GCP :
- Orchestration avec Cloud Scheduler
- Fonction de trigger : Cloud Function ou Cloud Run
- Données : BigQuery
- Monitoring : tableau de bord Lightdash ou Streamlit
- CI/CD: GitHub
✅ Résultat : une data plateforme moderne, cloud-native et totalement gratuite
| Atout | Pourquoi c’est utile ? |
|---|---|
| 🌍 Réalisme | Utilise des cas métier réels (ServiceNow, IA, KPIs, etc.) |
| 🧠 Apprentissage | dbt, BigQuery, Python, CI/CD, IA générative |
| 📈 Portfolio | Peut être partagé à un recruteur ou transformé en démo |
| 💰 Gratuité | Full free tier GCP + outils open-source |
C’est à mon sens une base intéressante pour monter son projet personnel, rien ne vaut la pratique et avec cette stack cela reste 100% gratuit!