
Avec l’émergence du rôle d’Analytics Engineer, la data entre dans le monde du Software Engineering : versioning, testing, documentation, déploiement automatisé… bref, du CI/CD 🛠️
Et la bonne nouvelle ?
Des outils comme dbt (core ou cloud) ou SQLMesh nous facilite cette transition.
🔁 Pourquoi faire du CI/CD dans la data ?
✅ Fiabiliser les transformations SQL
✅ Réduire les erreurs humaines
✅ Gagner en traçabilité et reproductibilité
✅ Tester avant de casser la prod 😅
✅ Générer automatiquement la documentation métier (avouez le, ce point est bien souvent négligé)
📦 La stack minimum viable ?
🔹 Git (GitHub, GitLab, Bitbucket…)
🔹 dbt (en local ou Cloud)
🔹 Un Data warehouse on premise (Oracle, Postgres…) ou en cloud (BigQuery, Snowflake, Redshift…)
🔹 Un orchestrateur (Airflow, dbt Cloud Scheduler, GitHub Actions…)
🧠 dbt, c’est quoi? :
dbt (data build tool) fonctionne comme un orchestrateur SQL versionné : tu écris des modèles SQL dans des fichiers .sql, tu les organises en couches (staging, intermediate, mart), tu les documentes et les testes via des fichiers .yml, et tu pilotes le tout avec Git. Chaque modification passe donc par un commit, une branche, une pull request — exactement comme dans un projet de dev classique.
organisation type d’un projet dbt:
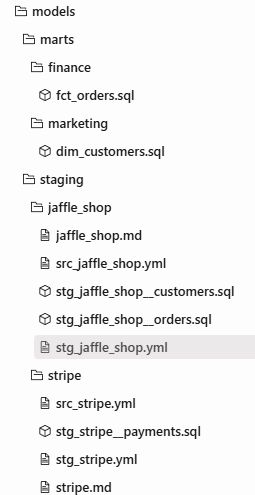
🔍 Les commandes dbt principales :
dbt run👉 Exécution des modèles modifiésdbt test👉 Vérification des contraintes (unique, not null, relations…) ou des tests fonctionnelsdbt docs generate👉 Génération de la doc HTML à jourdbt build👉 Compilation + tests + materialization en un seul run
🎯 Exemple concret dans un projet dbt :
Tu travailles sur une nouvelle règle de segmentation client, qui impacte la couche intermediate.
➡️ Tu crées une branche feature/segmentation_v3
➡️ Tu ajoutes/modifies un modèle int_kyc__segmentation_clients.sql
➡️ Tu mets à jour le fichier int_kyc.yml avec des tests :
models:- name: int_kyc__segmentation_clients
columns:
- name: client_id- description: identifiant unique du client
tests:
- not_null
- unique
- name: segment- description: la catégorie de segment du client
tests:
- accepted_values:
values: ['premium', 'standard', 'freemium']
➡️ Tu pushes une pull request → la CI peut ainsi vérifier :
✔️ que la transformation tourne (dbt run)
✔️ que les tests sont respectés (dbt test)
✔️ que la doc est bien générée (dbt docs generate)
Si tout passe, tu merges : le code est validé, documenté, testé ✅
Cette approche permet de sécuriser des projets sensibles (compliance, KPI réglementaires, modèles AML…) en assurant la qualité avant chaque mise en production.
#AnalyticsEngineering #DataEngineering #CI_CD #dbt #SQLMesh #DataQuality #ModernDataStack #SQL #DataOps